ITE4053_DL> 11-2 Convolution
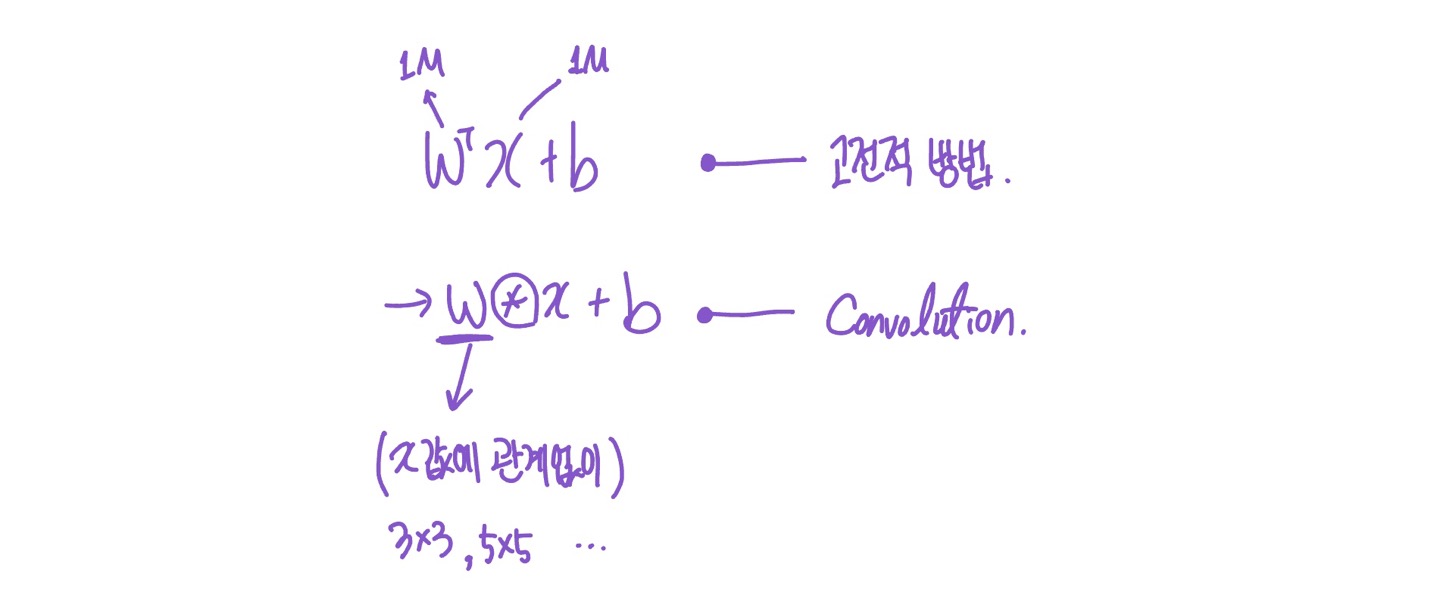
2D convolution은 affine transformation이다.
1D Convolution
전에 2차원 예시 봤었음.
descrete한 도메인이 아닌 continuous 한 도메인에서도 가능
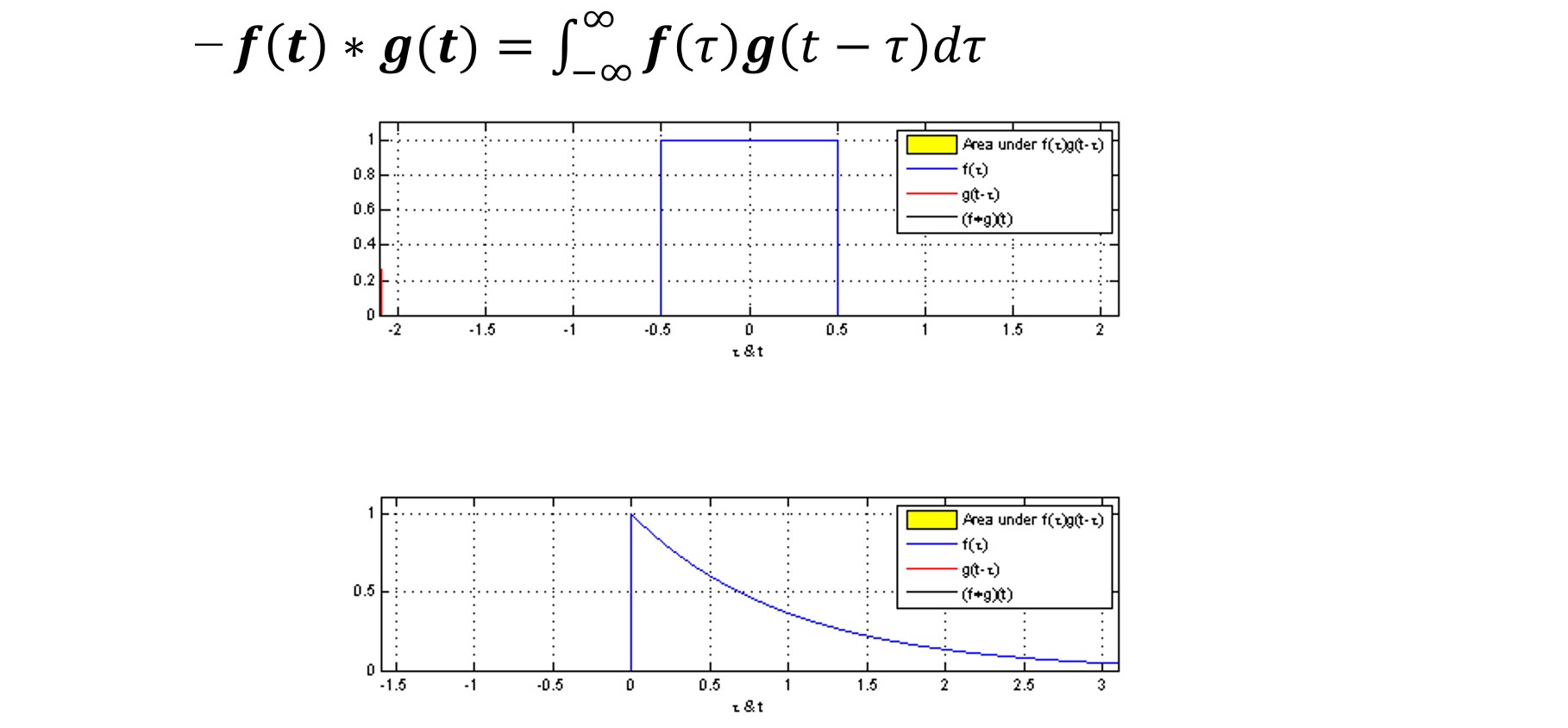
descrete 버전에선 수식이
$\sum$ 이었는데, continuous 에서는 $\int$
Computer vision problems
이미지 imput으로 받는 다양한 비전문제 잘 푼다고 알려져 있음
하지만 딥러닝에서 이미지 크기 커지면, 전통적인 뉴럴 네트워크로 다루기 힘들어진다.
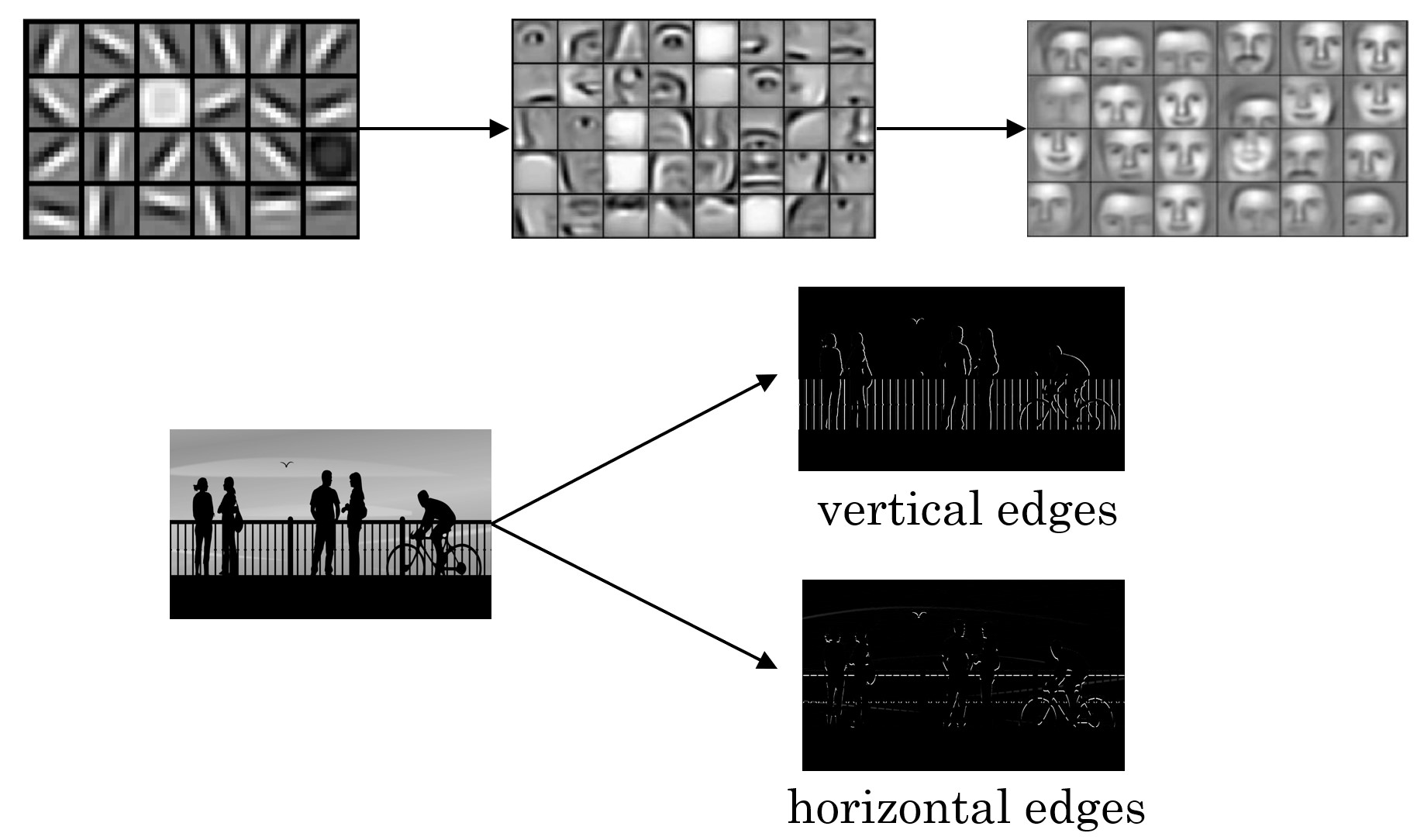
저수준은 edge map 정도 얻어지는 것. 이를 non-linear 하고, 다시 추출, 또 non-linear 적용 반복하면 결국 컨볼루션으로 이미지의 우측과 같이 특징 추출 할 수 있다.
Q. 그래서 무엇이 optimal filter value?
(= 어떤 필터를 써야 할까?)
A. 기존에 W 찾는 문제가 estimate filter coefficient로 (filter의 값 찾는 문제로 바뀜.)
Padding
-
패딩이 없는 경우, output의 크기가 작아짐.
-
large filter → 더 많은 패딩 적용해야함
-
이미지가 nxn 필터가 fxf일때 output은 (n-f+1)(n-f+1)
(output 크기 구하는 수식 알필요는 없음)
Strided
-
2strid → 2칸씩 띄어서 이동
-
boutput의 크기는 (촘촘히 했을 때보다) 크기가 작아진다.
-
bfeature의 resolution 줄이고 싶을 때 사용하기도 함
-

컨볼루션의 결과 크기 얻는 수식 있지만, 외울 필요 X
요즘은 api에서 다 해줌. 원하는 크기 써주기만 하면 됨.
CNN: Local Connectivity
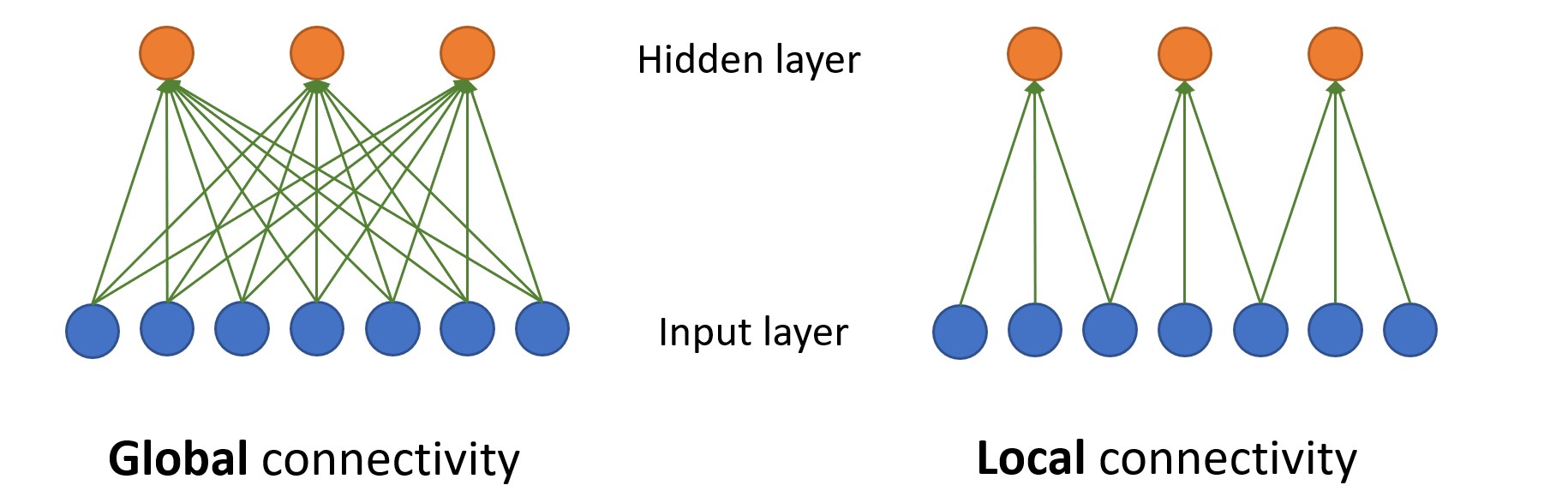
(이미지에서 하단 파란색은 7dimension의 input vector, 주황은 3units 기존 학습에서의 layer 1이라 생각)
파라미터의 개수가 21 -> 9 확 줄어든다.
- Global connectivity
지금까지 공부한 버전은, 모든 input이 모든 곳으로 들어감.
각 unit에서는 affine transformation과 non linear transform 진행.
- Local connectivity
각 unit은 3dimension vector를 input으로 받음.
따라서 7개 요구했던 좌측 버전과 달리 3개씩 필요.
기본적인 아이디어는 근처에 있는 데이터는 similar to each other
예를 들어 input 데이터가 비디오라면,
첫번째와 두번째(인접) → 연관성 높음
멀리 떨어진 frame → 연관성 낮음
따라서 전체 다 넣지 말고 거리 가까운(연관성 높은) 애들만 넣어주자,
→ 이렇게 되면 총 9개의 trainable parameter 있으면 된다.
수업 중 Q.
input unit하나가 비디오 한 프레임으로 봐야하는건지, 이미지의 한 픽셀로 봐야 할지
A. 상관 없다 둘다 가능. 문장에서 word라고 생각해도 됨.
CNN: Weight Sharing
local connectivity로 weight 개수 줄였는데, 파라미터공유해서 개수 더 줄일 수있다.
Q. 파라미터 개수 많으면 더 accuracy 올라가는데 왜 줄일까?
A. specific layer에서 local connectivity, weight sharing 통해 (파라미터 줄이고) layer 개수 늘릴 수 있음
레이어 하나에서 파라미터 개수 줄이고 레이어 개수 확 늘릴 수 있음.
단순히 파라미터를 줄인다보다 레이어 개수를 늘려 훨씬 복잡한 네트워크 만들기 위함
이를 컨볼루션에 적용하면,
filter 적용한건 곧 weight sharing한 것.
(하나의 filter로 전체 사용)
큰 이미지에서 맨 좌상단 픽셀 연산 할 때 우 하단 픽셀 고려하지 않음.
local 한 데이터만 사용함.
→ 이는 곧 local connectivity 적용한 것.
(입력을 한번에 다 처리하는 것 X)
CNN mulitple input, output
- input
single input 뿐만 아니라 multiple input 가능.
하나의 필터 for 하나의 specific 채널.
multiple input은 보통 채널 수 만큼 filter 씀
- output
필터 여러개를 쓰면 multiple channel output도 됨.
convolution on RGB images
multiple channel → multiple filter 필요함.
3x3 필터 쓴다면 27개의 parameter
채널이 3개면, 채널1, 채널2, 채널3 연산 후 더한 것이 convolution result.
(결과가 3개 처럼 보일 수 있는데, 최종 output은 셋 더한 것.)
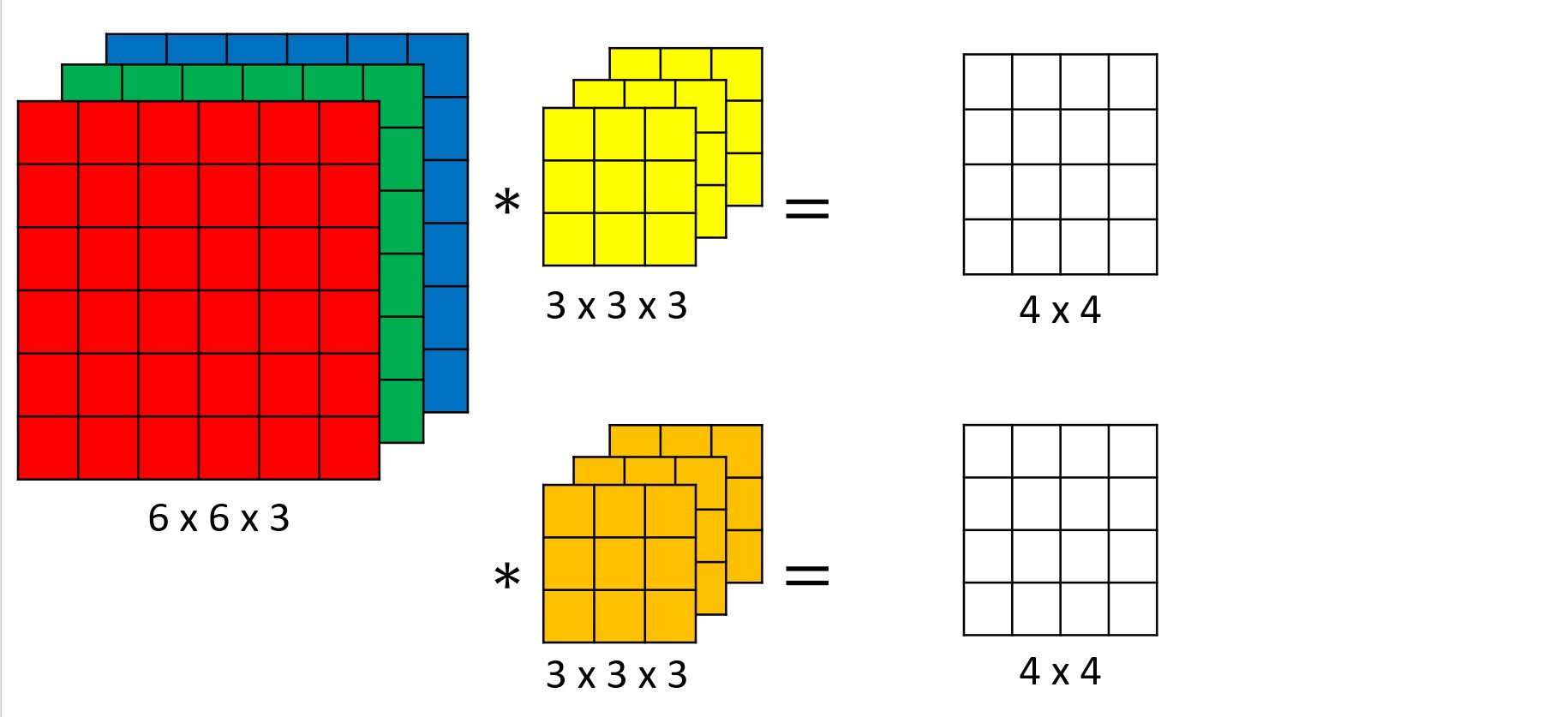
맨 좌측이 input, 맨 우측이 output
Multiple channel 위해선 additional filter
Example of a layer
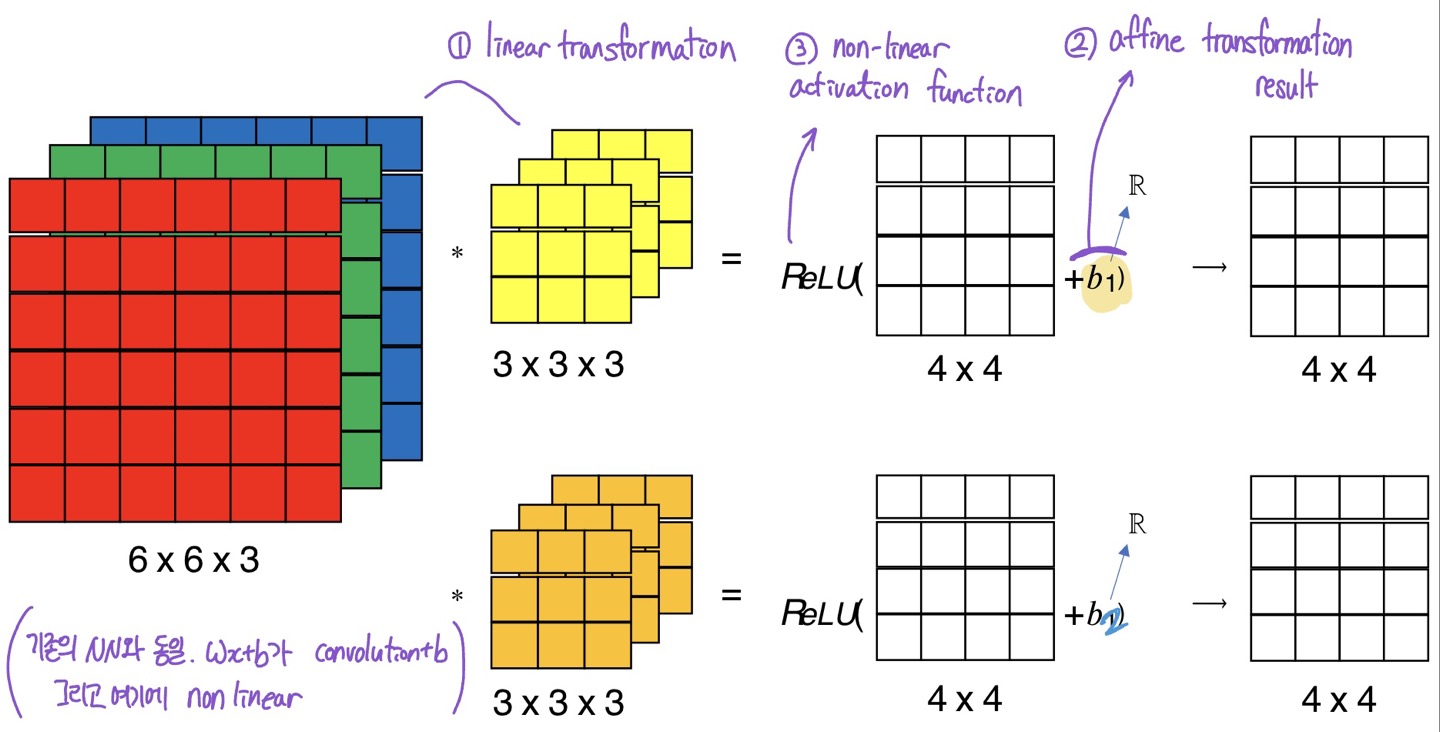
1) linear transformation
2) affine transformaiton
3) non-linear activation function
원래 NN와 동일.
wx+b → w (convolution) x+ b 로 바뀐 것
Number of parameters in one layer

A.
270개의 weight + 10개의 bias ⇒ 280개의 파라미터!
Q. channel of output은?
10
Q. channel of input은?
3
= filter의 마지막 수인 channel을 통해 알 수 있음
Q. input size는?
상관 없음. 입력의 크기가 뭐던 고정된 필터의 크기로 연산.
→ 기존 하던 연산과 convolution의 가장 큰 차이.
“filter 크기가 input의 resolution 결정하지 않는다”
Summary of notation

기억할 필요는 없음
[출처]ITE4053 수업