ITE4053_DL > 10 Hyperparameter Tuning and Softmax
10 Hyperparameter Tuning and Softmax
Hyperparameters

- 알파는 경사하강법 때 사용하고,
하이퍼파라미터 중 가장 중요한 것
- 베타는 smoothing 할 때 사용. 다른 값들과 함께 중요도 #2 하이퍼파라미터
하이퍼파라미터가 좀 더 많은 Adam사용 시 보통 디폴트 값 사용
- hidden unit의 개수, mini-batch 크기도 베타와 함께 중요도 #2 하이퍼파라미터.
하이퍼파라미터는 depend to each other
Try random values: Don’t use a grid
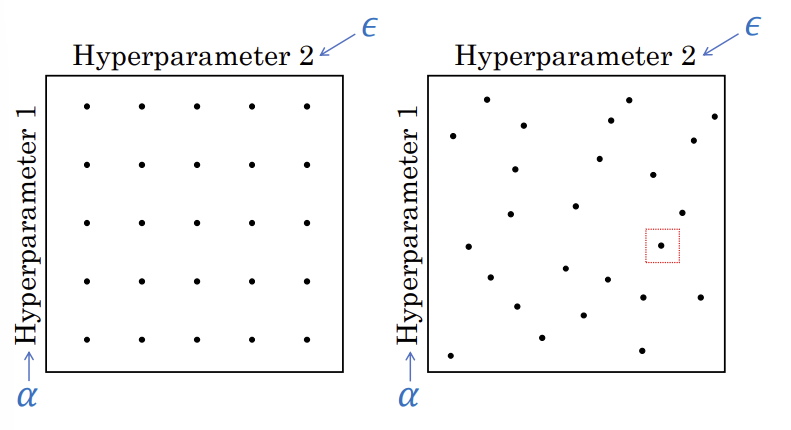
좌측 예시에서는 uniformed 되어있는 25개
우측은 randomly chosen 25개
Random 한 값 사용해야하는 이유:
Hyperparameter1을 알파, Hyperparameter2는 입실론이라고 했을 때 grid 쓰면 결국 5개의 알파값을 테스트 하는 것임(25개의 configuration있음에도 불구하고). 입실론도 마찬가지로 5개 값만 테스트
하지만 random sample에서 test한다면 25개의 알파, 입실론 테스트 하게 됨
→ (더 다양한 값의 하이퍼파라미터 테스트 해서) 더 나은 하이퍼파라미터 configuration가능
이전 슬라이드의 빨간색 박스가 가장 좋은 값이었을 때,
그 주변 더 자세하게 테스트 해서 나은 값 찾아봄
Picking hyperparameters at random
1000과 10001의 차이는 적은데
2와 3의 차이는 큼
랜덤하게 찾는건 좋은데 scale에 주의해야함
1000, 1001 이런데에 집중해서 search 하지말고 2,3 이런데서 더 주의해서 search
Appropriate scale for hyperparameters
그냥 완전히 랜덤하게 알파값을 선택하는 것이 아니라
값이 작을 때에는 더 dense하게 선택하고, 1주변(큰값 근처)에서는 sparce하게 선택하는게 더 나은 방향일 수 있다(optimal 한 것은 아님)
Re-test hyperparameters occasionally
하이퍼파라미터는 depend to each other(밀접하게 연관. 독립적이지 않음) 하기 때문에 하나를 변경하면 다른 것도 점검해봐야함
예를 들어 레이어 수가 2에서 3으로 바뀌었을 때 learning rate가 이전과 동일한 것이 잘 맞는게 아닐 것임
휴리스틱 to determine 하이퍼파라미터
Softmax
Softmax activation의 output layer로 많이 사용
4개의 class → 4개의 output 종류
지금까지는 binary classification문제 봤는데 더 제네럴한건 muti lable classification.
레이블이 많은 경우.
각각의 output이 의미하는건 0번동물일 확률, 1번 동물일 확률 …
다 양수여야하고, 전체합이 1이 되어야 함.
그러면 normalization필요하다. 그래서 softmax 사용
Softmax 수식으로 표현
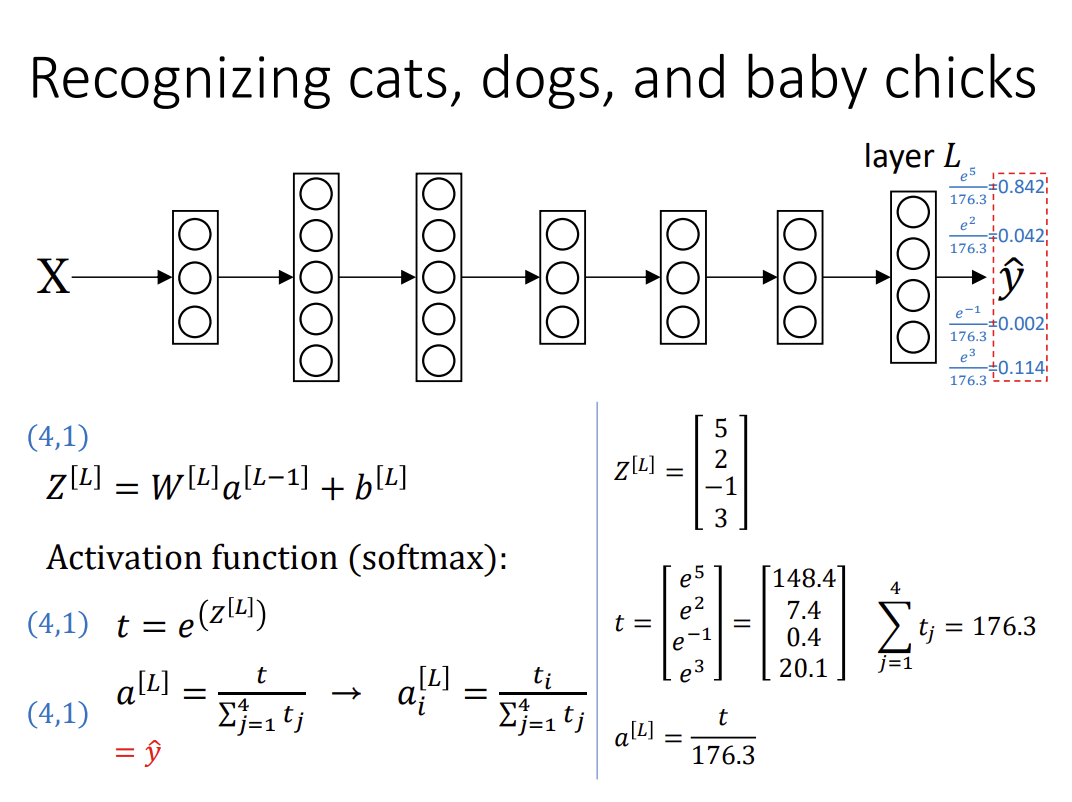
“logit”(?) → z
z는 -$\infin$ ~ +$\infin$의 값 가질 수 있음
확률값으로 보이게 하려면 exponential 안에 넣어 양수로 만들고.
t는 항상 양수 값 가짐
다음 줄에서 합이 1이 되게 하려고 하는 처리 부분.
이것이 softmax.
binary는 activation으로 sigmoid 썼었는데 multilayer의 경우는 소프트맥스 사용.
지금까지는 output 레이어의 노드가 하나였는데, 여러개와 큰 차이 없음.
요약)
Z → t를 통해 다 양수 값으로 바꾸었고,
t → a 를 통해 전체 합이 1이 되도록 변환 함

Binary cross entropy loss 가 아닌 cross entropy loss사용
C가 2인 경우가 BCE(?)

미분이 안되는 연산은 들어올 수 없음!!
differential 하고 연산도 너무 오래 걸리면 안됨.
소프트맥스는 너무 복잡하지도 않으며 미분도 가능함.
[출처1]ITE4053 수업