Classification (2/2)
ITE4005_DS > (6-7) 6
[Data Science]6 Classification PART 2
목차
(part1)
- What is classification?
- Issues regarding classification
- Classification by decision tree induction
- Random Forest
(part2)
- Rule-based classification
- Associative classification
- Lazy learners (or learning from your neighbors)(k-NN classifiers)
- Accuracy and error measures, protocols
- Ensemble methods
- Summary
Rule-based Classification
: classification이 rule에 의해 이루어짐.
데이터가 적은양이거나 없을 때 사용하는 방법
human expert가 rule 만들 수 있음
Example
- rule의 예
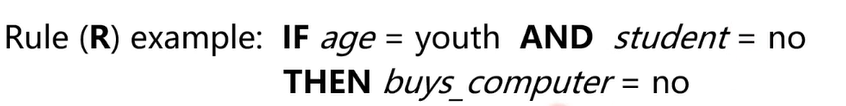
하지만 rule-based classification에는 **conflict** (if more than one rule is triggered)문제가 있음
-
conflict 예시,
-
rule A: IF age= youth AND student= no AND credit= fair THEN buys_computer= no
-
rule B: IF age= youth AND student= no AND location= 용산 THEN buys_computer= yes
-
이 경우 한 사람에 대해 conflict 발생할 수 있음
(“age= youth, student= no, credit= fair, location= 용산” 인 사람에게)
conflict 해결법:
-
Size ordering
rule의 size = feature의 개수(만약 rule 조건이 if A and B and C → size 3)
toughest rule(largest size rule)에 높은 priority를 부여. -
Class-based ordering
우리가 가지고 있는 각 rule test. 그 중 misclassification 적은 rule 선택 -
Rule-based ordering
domain expert에게 요청할 수 o?
⇒ 2개 이상의 rule이 다른 결정을 내린다면 크기, misclassification, predefined 등에 의해 priority 정의할 수 있다.
Rule extraction from a decision tree
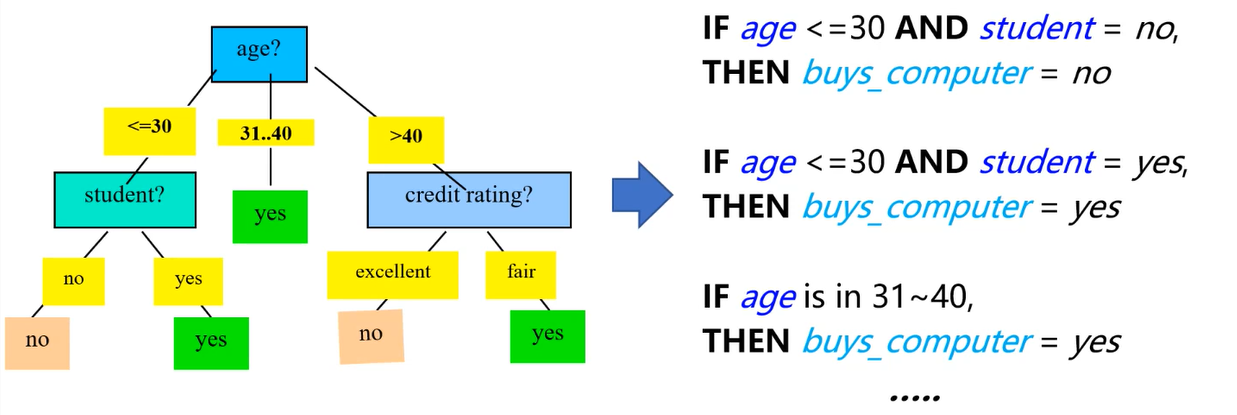
Q. Decision tree와 rule based classification 같은 방식으로 동작하는데 왜 rule을 extract 하는가?
A. tree의 크기가 큰 경우 decision tree의 내부에서 무슨 일이 일어나고 있는지 이해하기 어려울 때 있음. 이 때 rule을 list up 하게 되면 상대적으로 이해 쉬움
-
rule하나와 tree의 시작점부터 leaf까지 한 줄(path) 대응.
-
한 path의 leaf 제외하고는 모두 if 조건 부분(conjunction), 마지막인 leaf가 classification part.
-
모든 rule을 decision tree에서 추출한다면 exclusive (no conflict)
☑️ 헷갈리는 주제 ☑️
Associative classification
= Rule Extraction from Association Rule Mining
모든 rule은 associative rule mining의 결과에서 추출.
{A B C D E} 에서 C가 class feature 라면 {A B D E} → {C}
다른 예시로, {p1, p2, … , pl, A=C}가 있을 때 (이건 Apriori나 fp-growth로 생성)
이후 class feature가 있기 때문에 {p1, p2, … , pl}→ A=C 라는 association rule을 만들 수 있고, 이를 classification에 사용할 수 있음
-
associative classification은 rule based classification.
그리고 rule은 frequent pattern mining에 의해 만들어질 수 있음
-
min_sup. and min_conf., 컨트롤 하는 것을 통해 적은 수지만 confident 한 rule을 얻을 수 있음.
-
하지만 mutually exclusive 하지 않음 (= conflict일 수 있음). 따라서 이전에 본 conflict 제거 method 사용해야 함
-
장점과 한계
- 장: higher min confidence를 설정해서 적은 수의 highly confident association
- 단: higher min confidence를 설정하면 low coverage 문제가 생길 수 있음
Coverage and accuracy of a rule R
n_{covers} = # of data covered by R = the # of data point that rule can cover
n_{correct } = # of data correctly classified by R = the # of data point that correctly classified by this rule
“covered”란 그 rule에 의해 classified 된 data의 수
$\therefore coverage = $ $전체 data 수 \over {cover한 data수}$
coverage(R) = n_{covers} / |D| /* D: training data set */ accuracy(R) = n_{correct} / n_{covers} = correct 하게 분류한 수 / cover 한 data
coverage와 accuracy 두개는 traning phase에서 측정 됨
Lazy vs. Eager Learning
eager learning
-
대부분의 머신러닝은 eager learning 을 따름 (typical & normal approach)
-
triaining set이 주어졌을 때 classification model을 (classify 할 새로운 데이터 받기 전에) 만든다.
-
huge amount of time 걸리지만, classification 모델을 만듦.
lazy learning
-
단순히 training data 저장 (혹은 매우 적은 preprocessing) 후 test data가 주어지기 전까지 기다림.
-
이후 test data가 주어졌을 때 classification 시작.
⇒ training에서 훨씬 적은 시간. 하지만 predicting에서 더 많은 시간
The k-Nearest Neighbor (KNN) Algorithm
- n-dimensional space에서, distance를 정의할 수 있음(유클리디언, 맨하탄 distance 등)
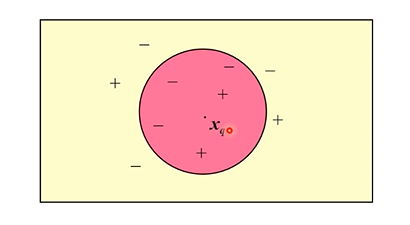
-
위와 같이 10개의 data가 주어진 경우(-와 +는 class lable), 새로운 test sample이 들어오기 전까지 기다림
-
이후 x_{q} test 샘플이 들어온 경우, 이를 training데이터에 기반해서 classify 하고싶음.
-
k-nearest lable = target node인 test sample에 거리가 최소인 데이터 포인트
-
만약 1-nearest neighbor classification이면 가장 가까운 한 점이 선택될 것이고,
만약 5-nearest neighbor classification이면 가까운 다섯개의 점이 선택될 것이다.
만약 5-nearest neighbor classification로 5개의 점이 선택 되었다면, 이는 어떻게 classified by sample?
→ majority voting 2개의 +가 있고, 3개의 -가 있기 때문에 -로 판단. - 결국 정리하자면,
어떠한 classifier도 test case들어오기 전까지 training 하지 않음
이후 test case들어오고 classification 시작. 단순히 근처 k개의 데이터 보고 majority voting. - 하지만 voting 할 때 weighted voting 할 수 있음.
위 예시의 경우 +가 상대적으로 -에 비해 거리가 가까움. 따라서 이 거리에 비례해 가중치를 주어 voting할 수 있음. 이렇게 되면 결과 달라질 수 있다.
Model evaluation
Accuracy evaluation
- 평가 시 test data 사용. training data와 format 동일한(n개의 feature와 class label)
- 만든 model 에 test data 넣으면 classification 된 결과가 나오고 이를 test sample의 label과 비교
- 정확도 = 옳게 분류된 # / 전체 data set의 #
- test set은 training set과 independent 해야함. 다시 말해서 두 data는 disjoint
confusion matrix
: “accuracy” 개념 더 디테일하게
-
fully trained model 있고, test data로 test 하는 단계
-
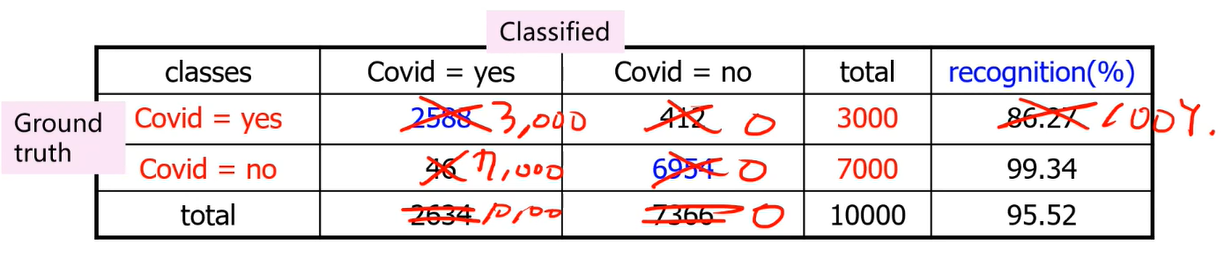
binary YES, NO 분류 문제는 아래와 같이 4개로 분류된다.

(여기서 ground truth는 original class label)
test label과 model이 분류한 결과를 비교해 count +1 시킴.
이후 전체 데이터에서 옳게 분류된 것의 비율이 Accuracy 임
accuracy의 반대말인 Error rate는 (1- accuracy)
아래 예시에서는,

Accurracy = (2588+6954) / 10000
sensitivity (=recall) 수치 boost 하는 법
: 모두 YES라고 판별하기
이러한 문제를 precision으로 잡을 수 있다.
이 경우 precision 30%
둘중 하나만 보면 문제 있을 수 있다
precision 수치 boost 하는 법
: 확실한 적은 케이스만 YES라고 판단
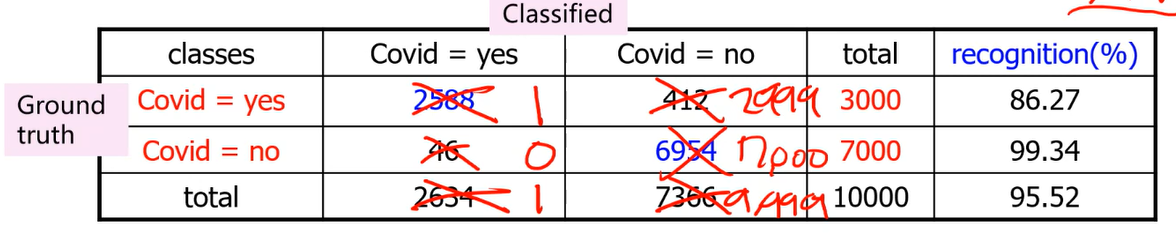
이 경우 precision = 100%
하지만 이 경우 recall의 값으로 1/3000 대략 0.1미만의 값이 나오게 됨
따라서 model evaluate 할 때 sensitivity , precision 둘 다 봐야 함
⇒ sensitivity , precision 둘 다 고려하는 F1-score 많이 사용됨

Evaluation Protocols
모델의 accuracy 평가하는 방법은,
어떻게 모델 전체를 training data와 test data로 나누는가에 대한 문제(?)
- Holdout method
- 랜덤하게 파티션된 두 independent set
- Training set - 모델 construction용
- Test set - 모델 평가용
- 추가적으로 신뢰성(reliability)올리기 위해 K회 반복 할 수 있음(partition 바꿔가면서)
- 이때 Accuracy는 K회 진행한 것의 평균
- 랜덤하게 파티션된 두 independent set
- Cross-validation(= k-fold cross validation)
- K개의 subset으로 랜덤하게 나눔(각 subset은 동일한 사이즈)
- 각 subset은 fold 라고도 함
- K개 중 한개를 evaluation set으로 사용, 나머지를 training set으로 사용
- 다음 반복 시에는 두번째 set을 evaluation set으로, 나머지를 traning set으로. 이것을 K회 반복
- 보통 K 값은 5, 10으로 잡음
- 이 때 최종 Accuracy는 k회의 accuracy의 평균
- Leave-one-out
- k-fold cross validation의 특이한 케이스
- 작은 크기의 데이터를 가지고 있을 때 많이 사용함.(매우 많은 iteration)
- K = # of data point
- 각 set은 한 data의 크기의 set이므로, 매 회마다 한 데이터가 evaluation용으로 쓰이고 나머지는 train에 사용.
- Stratified cross-validation
- 이것도 마찬가지로 k-fold cross validation의 특이한 케이스
- 각 fold는 stratified 되어있음. class 분포(distribution)가 대략 유사함
- 원래 전체 데이터에 spam 메일이 40%, 일반 메일이 60%라면 각 fold에서의 비율도 대략 4:6을 가지고 있음
Ensemble
: classification의 accuracy 증가시키는 방법
한 모델을 사용하는 것이 아니라 K 개의 모델을 만들고 여러 opinion을 aggrigate
popular 한 앙상블 method 들
- Bagging : 단순히 각 classifier들의 prediction을 평균 (Majority voting)
- Boosting : weight를 고려
- Model ensemble : 위 두개는 single type of classifier 합하는 것. 하지만 model ensemble은 다양한 종류의 모델을 합함. (예를 들어 SVM, Decision tree, NN 동시에 사)
(Bagging, Boosting 디테일하게)
Bagging
: Bootstrap Aggregation의 약자
Based on Bootstrap sampling. (랜덤 포레스트 할 때 다뤘었음)
Bootstrap도 모든 decision tree의 값 majority voting으로 aggregate함.
랜덤포레스트는 bootstrap에 based. 그러나 랜덤포레스트는 weight도 고려하기도함.
따라서 랜덤포레스트는 Bag 전략 취할수도, Boost 전략 취할 수도 있음
weight 고려 안하면 Bag, 고려하면 boost
Training>
-
sample 된 set들로 각 모델을 훈련 시킨다
-
classifier model $M_{i}$는 각 training set $D_{i}$로 학습
classification>
-
학습한 model 들에 unknown variable X를 넣으면 각 모델에서 class prediction을 return 한다.
-
각 모델들이 vote하고 가장 많은 vote를 받은 class로 최종 assign.
☑️ 헷갈리는 주제 ☑️
Boosting
: Weight를 고려한다.
(weight는 모델의 accuracy에 기반)
process>
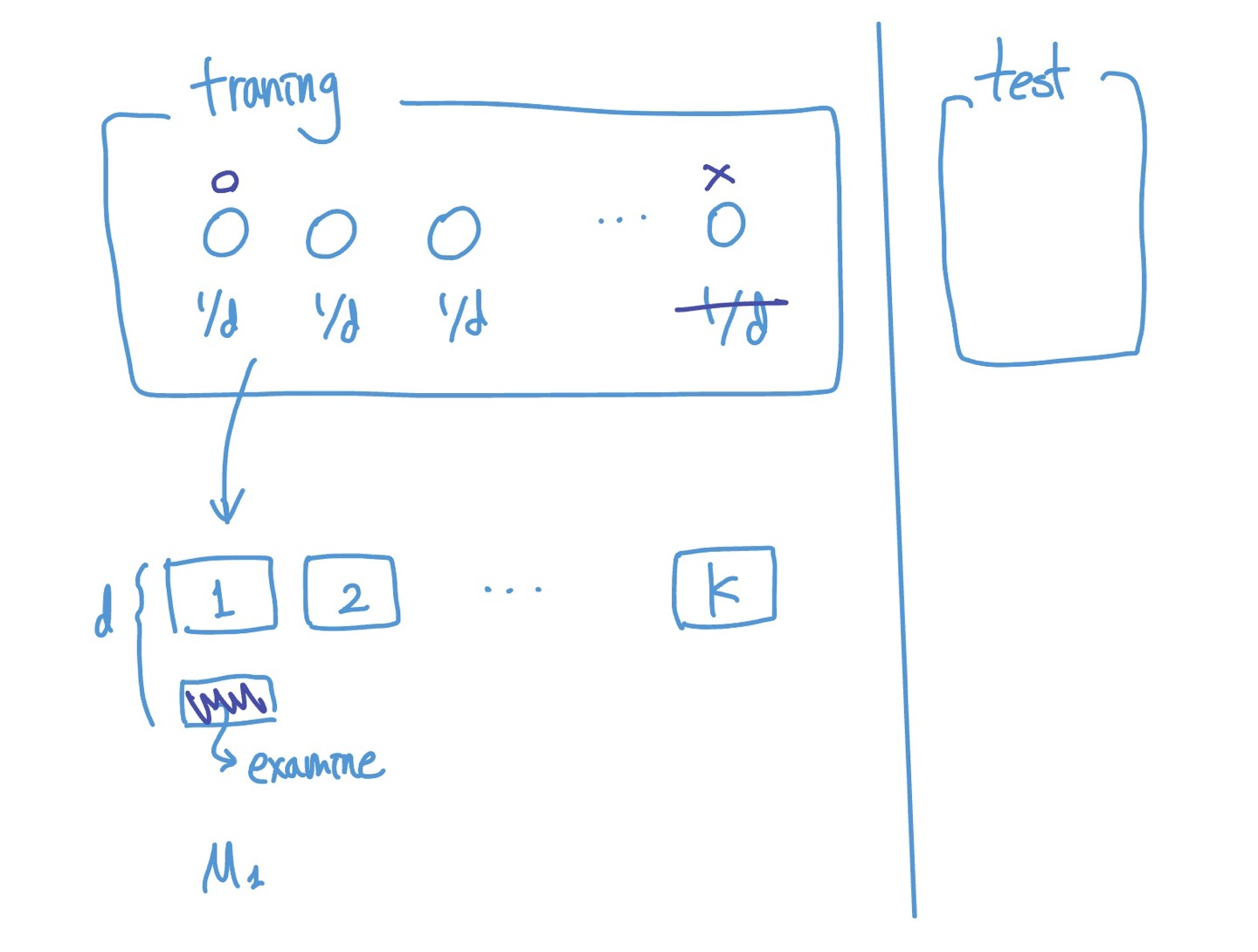
균등하게 나누어진 weight가 각 data point에 assign됨
?? sampling 할때에도 weight가 사용되었다고 하는데, 잘 모르겠음
k개의 set으로 k개의 모델을 훈련 시킨다.
이때 training set에 선택되지 않았던 데이터들(i-th test set로 test 해본다. (여기서 test 해보는 set도 전부 training / test 나눈것 중 training에서 안쓴 데이터를 가지고 test ‘해보는것’임. 특정 한 iteration만을 위한 train set인것)
만약 test set에서 틀리게 예측한 경우 weight 업데이트.
값 더해줌으로 써 다음 모델에서 더 집중하도록(pay more attention) 함.
최종 결과는 각각의 classifier에서 판단한 값에 weight 고려된 값
위는 하나의 boosting 예시. 다양한 방법 있음
https://ybeaning.tistory.com/17
*Bootstrap Bagging Boosting 정확이 알기 현재 헷갈리는 상활
출처 : 2023-1 ITE4005 수업