Basic SQL
ITE2038 Database Systems
Introduction
-
SQL은 high-level language
“어떻게 할지”가 아닌 “무엇을 할지”를 표현. -
DBMS는 쿼리를 수행할 “best” way를 찾음.
= query optimization
SQL
- SQL문의 종류중 두가지
-
- Data Definition Language (DDL) = 데이터 정의어
- 데이터의 전체적인 골격 결정하는 역할
DB관리자나 설계자가 주로 사용
schema, table, view, index를 정의, 변경, 삭제 시 사용하는 언어
-
- Data Manipulation Language (DML) = 데이터 조작어
- 입력된 레코드 조회, 수정, 삭제 하는 역할 DB사용자가 쿼리문 통해 데이터 실질적으로 처리하는데 사용
-
Tables
- table의 세로축인 열 : Attribute names
- 가로축인 행 : Tuples…
Tables Explained
- table의 schema = table name과 attribute들.
Product(PName, Price, Category, Manufacturer) - Primary key = table에서 값이 unique한 attribute
밑줄로 표현
Data Types in SQL
Atomic types:
- Characters: CHAR(20), VARCHAR(50)
- Numbers: INT, BIGINT, SMALLINT, FLOAT
- Others: DATE, DATETIME, TIMESTAMP, …
attribute들이 atomic하기에 더이상 분할되지 않는 하나의 값을 가지게 되고, 이는 데이터의 일관성과 효율성을 위한 것.
DB의 테이블이 flat하게 설계된것과 관련.
SQL Query
기본적 형태
SELECT <attributes>
FROM <one or more relations>
WHERE <conditions>
Example
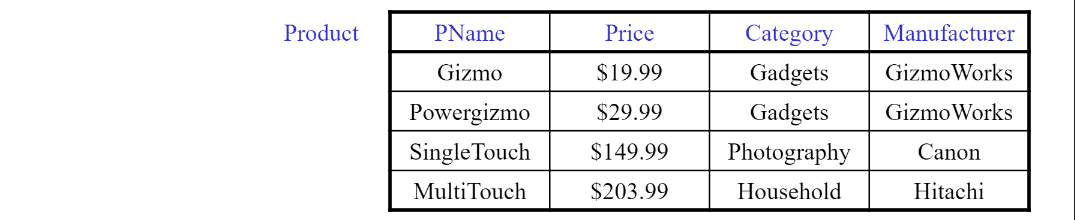
selection
SELECT *
FROM Product
WHERE category = ‘Gadgets’

selection and projection
SELECT PName, Price, Manufacturer
FROM Product
WHERE Price > 100

Notaion
Input relation:
Product(PName, Price, Category, Manufacturer)
(primary key에 밑줄)
Output relation:
Answer(PName, Price, Manufacturer)
Case insensitive
- Same: SELECT Select select
- Same: Product product
- Different: ‘Seattle’ ‘seattle’
‘LIKE’ operator
SELECT *
FROM Products
WHERE PName LIKE'%gizmo%'
s LIKE p: string에 pattern 매칭되는 것p에 들어갈 수 있는 특수문자 2개%: 문자열 가능_: 단일 character 가능
‘DISTINCT’로 중복제거
- DISTINCT 없으면,
SELECT category FROM Product$\downarrow$
| Category |
|---|
| Gadgets |
| Gadgets |
| Photography |
| Household |
- DISTINCT로 중복 제거,
SELECT DISTINCT category
FROM Product
$\downarrow$
| Category |
|---|
| Gadgets |
| Photography |
| Household |
결과 Ordering
SELECT pname, price, manufacturer
FROM product
WHERE category = ‘Gadgets’ AND price < 50
ORDER BY price, pname
- 첫번째 ordering 항목(위 예시에선 price)으로 동일 순번인 경우, 두번째 항목으로 순서 구분.
DESC를 붙이지 않는 이상 오름차순.
DB fiddle로 연습
Schema (PostgreSQL v11)
CREATE TABLE Product(
PName VARCHAR(30),
Price VARCHAR(30),
Category VARCHAR(30),
Manufacturer VARCHAR(30),
primary key(Pname)
);
Insert INTO Product VALUES
('Gizmo','$19.99','Gadgets','GizmoWorks'),
('Powergizmo','$29.99','Gadgets','GizmoWorks'),
('SingleTouch','$149.99','Photography','Canon'),
('MultiTouch','$203.99','Household','Hitachi');
Query #1
SELECT Category
FROM Product
ORDER BY Pname;
| category |
|---|
| Gadgets |
| Household |
| Gadgets |
| Photography |
Primary Keys and Foreign Keys
문득 sql 쿼리 작성 시 ‘WHERE Manufacturer = CName’ 등을 통해 join을 한다면, CREATE table 할 때 foreign key라는것을 명시하지 않아도 되는거 아닌가? 하는 의문이 들었다.
Foreign key가 두 table을 연결하는 역할을 한다는 개념은 알았지만 실질적으로 필요한건가? 라는 의문이 들었다.
알고보니, foreign key는 데이터의 무결성을 보장한다고 함.
무결성 보장하는 하나의 예로, Foreign Key로 설정된 필드에는 참조하는 테이블에 존재하는 값만 입력할 수 있게 되어, 잘못된 데이터의 입력을 방지할 수 있다.
결국 SQL 쿼리는 데이터를 조회하거나 조작하는 데 사용되는 것이고, Foreign Key는 데이터베이스의 구조를 설계하고 데이터의 무결성을 보장하기 위한 것이기 때문에 위 의문에 대한 답은 “명시가 필요하다!”이다
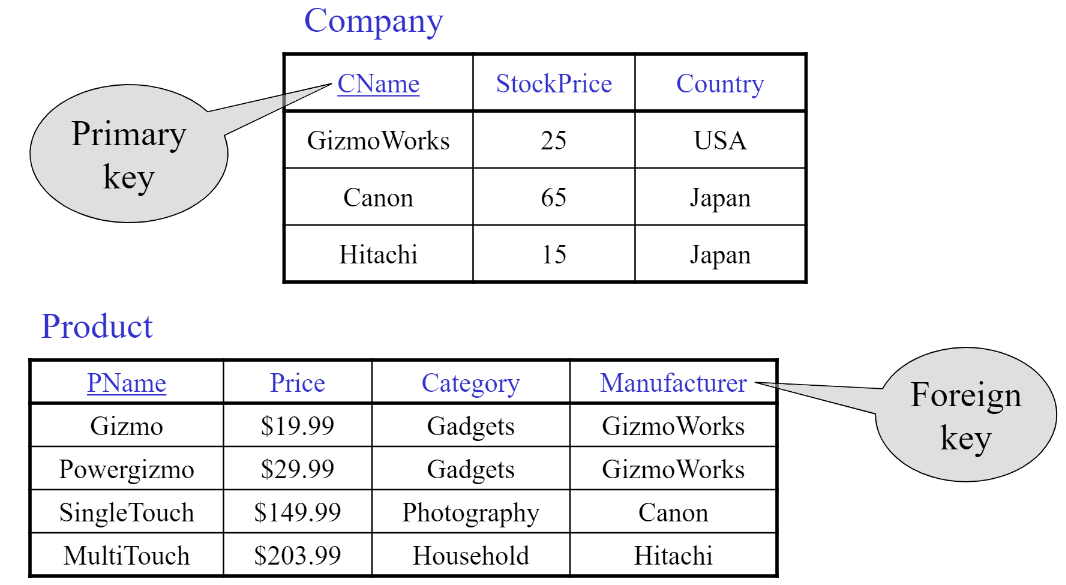
foreign key SQL문으로 작성하는것도 확인하기!!
Joins

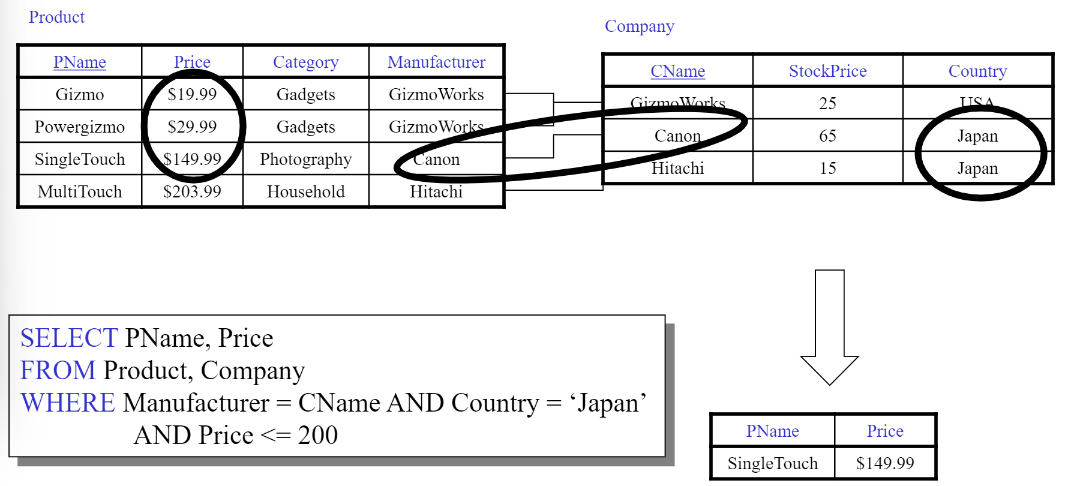
위의 예시 DB fiddle에서 확인
Schema (PostgreSQL v11)
CREATE TABLE Product(
PName VARCHAR(30),
Price INT,
Category VARCHAR(30),
Manufacturer VARCHAR(30),
primary key(Pname)
);
CREATE TABLE Company(
CName VARCHAR(30),
StockPrice INT,
Country VARCHAR(30),
PRIMARY KEY (CName)
-- FOREIGN KEY (CName) REFERENCES Product(Manufacturer)
);
Insert into Product values
('Gizmo',19.99,'Gadgets','GizmoWorks'),
('Powergizmo',29.99,'Gadgets','GizmoWorks'),
('SingleTouch',149.99,'Photography','Canon'),
('MultiTouch',203.99,'Household','Hitachi');
Insert into Company values
('GizmoWorks',25,'USA'),
('Canon',65,'Japan'),
('Hitachi',15,'Japan');
Query #1
SELECT PName, Price
FROM Product, Company
WHERE Manufacturer = CName AND Country ='Japan' AND Price <= 200;
| pname | price |
|---|---|
| SingleTouch | 150 |
#56
Grouping and Aggregation
SELECT S
FROM
출처 : 2023-2 ITE2038 수업