Database Internals
ITE2038 Database Systems
Contents:
- Relational database design
- Normal forms
Database Internals
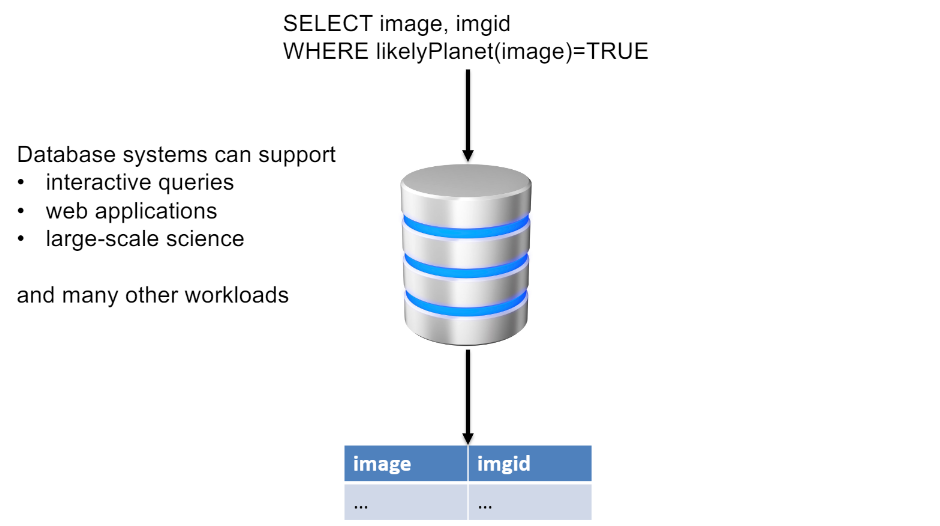
DB가 어떤 component로 구성되고, 각각이 어떤 기능을 가지고, 쿼리 던졌을 때 실행 순서…
결함없는 상태로 저장되도록.
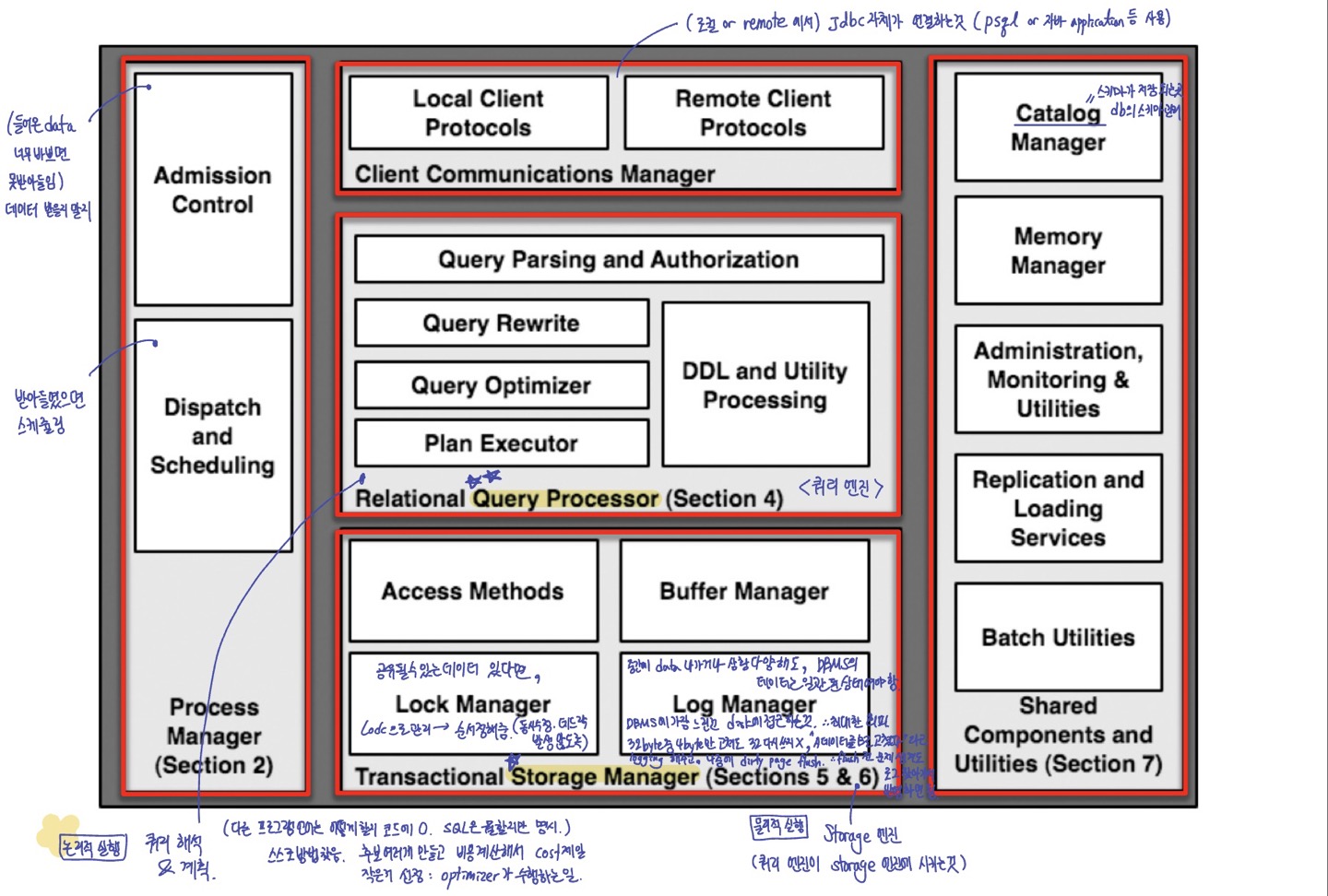 이런 구조 가지고 있음.
이런 구조 가지고 있음.
DB Core components
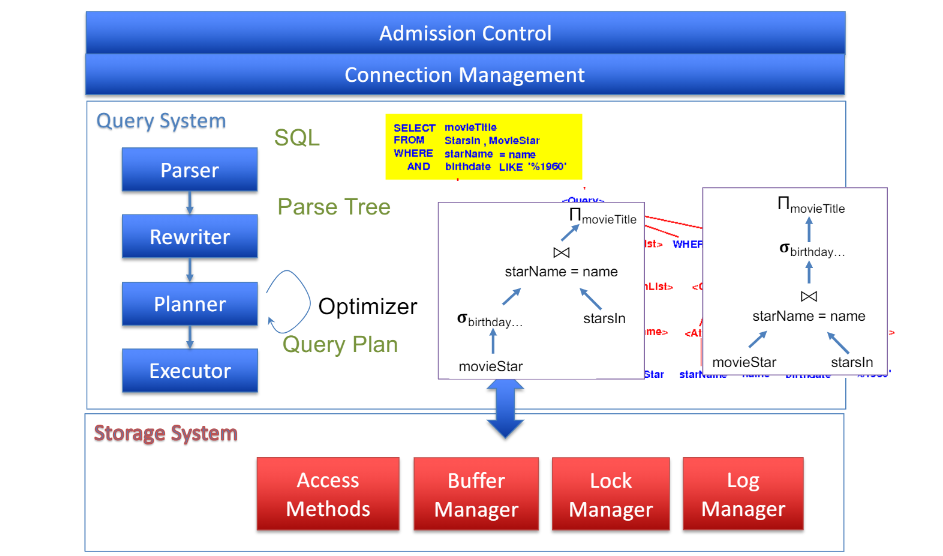 쿼리가 들어왔을 때,
쿼리가 들어왔을 때,
군더더기 제거, sub쿼리는 풀어서 작성 등 전처리 해주고, ->
여러 plan 세움. plan들의 비용 계산, 비교. 이후 비용적은 것 선택. ->
storage 엔진에 일 시킴
Query Processing Steps
- Admission Control
- Query Rewriting
- Plan Formulation(SQL->Tree)
- Optimization
1) Admission Control
지금 처리할 수 있는지 처리용량 확인.
처리할 수 있다면, 쿼리당 worker 할당되고, 다음단계 진행
2) Query Rewriting
대표적인 전략들
- View Substitution
- Predicate Transforms
- Subquery Flattening
View Substitution
sub쿼리 싫다! 최대한 풀어쓰자
Example
eecs 부서에 속한 사람들의 평균 sal(월급)을 구하려는 쿼리가 우측 형태로 들어온 경우, 이를 view를 사용한 죄측 형태로 바꿔줌.
Predicate Transforms
지저분한 쿼리 다 쳐냄. 쿼리를 간단하고 clear하게.
- constant simplification
WHERE sal > 1000 + 4000위 쿼리를,
WHERE sal > 5000간단하게 수정.
- Exploit constraints
a.did = 10 and a.did = dept.dno and dept.dno = 10위의 경우 중앙의
a.did = dept.dno에서 join 한것이므로 맨앞과 맨뒤 조건 둘 중 하나만 있으면 됨.
이와같이 중복되는 표현등을 지워주는 단계.
Subquery Flattening
sub쿼리 최대한 없애고, join 처럼 변경
 위와 같이 sub쿼리 형태로 작성된 부분을 join처럼 변경.
위와 같이 sub쿼리 형태로 작성된 부분을 join처럼 변경.
하지만 항상 가능한 것은 아님. 기계적으로 rewriting불가. 맥락 들어가야함.
❗Query flattenting 시 결과 달라지지 않도록 주의
SELECT dept.name
FROM dept
WHERE dept.num_machines >=
(SELECT COUNT(emp.name)
FROM emp
WHERE dept.name=emp.dept_name)
위 쿼리 flatten 했을 때,
1:
SELECT dept.name
FROM dept, emp
WHERE dept.name = emp.dept_name
GROUP BY dept.name, dept.num_machines
HAVING dept.num_machines >= COUNT(emp.*)
2:
SELECT dept.name
FROM dept
LEFT OUTER JOIN emp ON (dept.name=emp.dept_name)
GROUP BY dept.name, dept.num_machines
HAVING dept.num_machines >= COUNT(emp.name)
위 두가지 중 1번은 원래 쿼리와 결과 동일하지 X.
WHERE부분에서 직원수 0명인 부서는 결과에 들어가지 않음.
3) Plan Formulation(SQL->Tree)
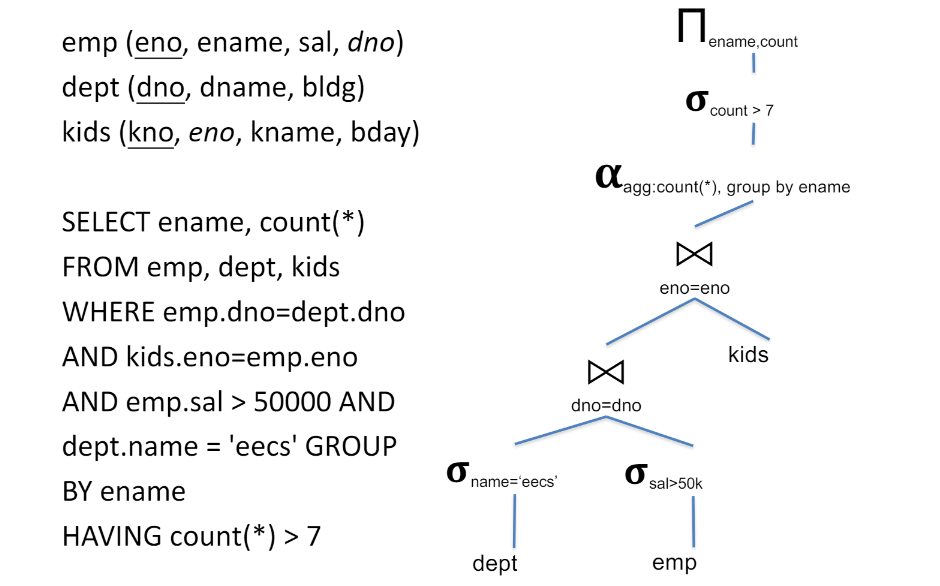 한 쿼리도 연산자들의 조합이 다양하기 때문에 여러방법이 있을 수 O.
한 쿼리도 연산자들의 조합이 다양하기 때문에 여러방법이 있을 수 O.
SQL을 tree 형태로.
다양한 조합 중 가장 빨리 실행 되는 조합을 선택하는 것이 쿼리엔진이 하는 핵심. (이후 여기서 결정된 plan을 storage 엔진에 보내는 것.)
4) Optimization
logical planning
다양한 operator의 조합 결정
-> 쿼리엔진
physical planning
파일처리와 관련된 물리적 수행
-> 물리엔진
Physical Layout
DB의 정확성은 당연한 조건이고, 시간이 관건. disk접근은 cost $\uparrow$ $\therefore$ 디스크의 접근을 줄이고자 함.
인덱스를 만들어두면 큰 table에 접근할 필요 없이 조금 더 빨리 접근 할 수 있게 됨.
스키마를 설계할 때 table, attribute, key, constraint를 설계했는데 여기에 일반적으로 인덱스까지 생성하는 걸 스키마를 설계했다고 함.
디스크의 레코드 배열
-
- Row Major
- 우리가 지금까지 본 방식. record별로 저장되어있음
-
- Column Major
- table을 세로로 자른 것.
레코드별로 저장되어있어 내가원하는데이터는 조금인데 전체 레코드를 읽어와야하는 비효율성 제거하고자 data를 column별로 저장한 것
(나중에 다시 나옴. 우선 Row major라고 생각하자!)
Accessing Data
Access Method: 파일 어떤 순서로 접근해서, 내가 원하는 data 가장 적은 접근횟수로 가져올 수 있는지.
-> 이게 point
Index
파일 접근할 때 최악의 경우, 아무 metadata가 없어서 파일 전체를 읽는 full scan.
(따라서 보통 index 사용)
빈번한 접근 한다면, 비효율 없애기 위해 index사용!
특정한 value를 가지고, 혹은 특정 range가지고 특정위치 찾아가는 것
Tree Index
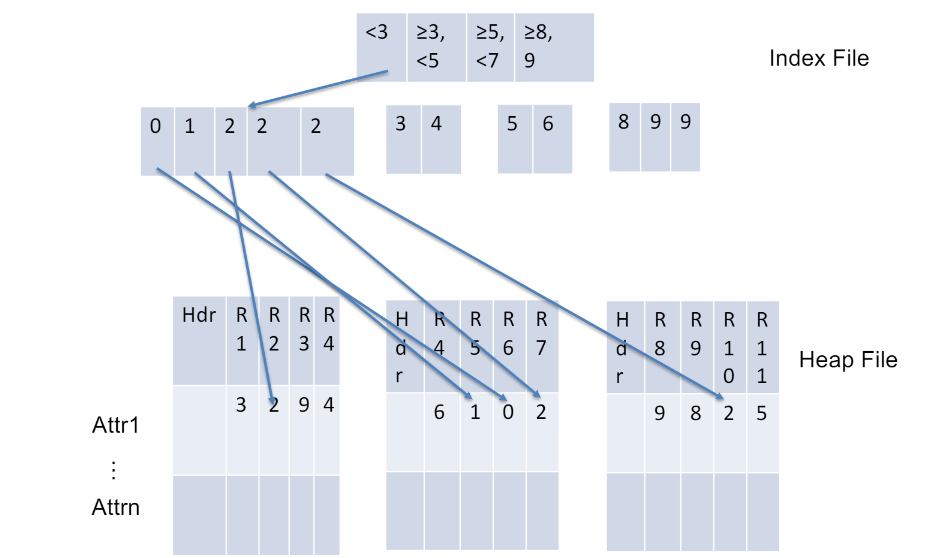
숫자로 범위 구분 가능한 attribute라면, 위 그림처럼 tree 형태로 하기도 함.
만약 이런 indwx없다면, 모든 data확인해야 함.
(index있다면 일부만 확인)
Clustered Index
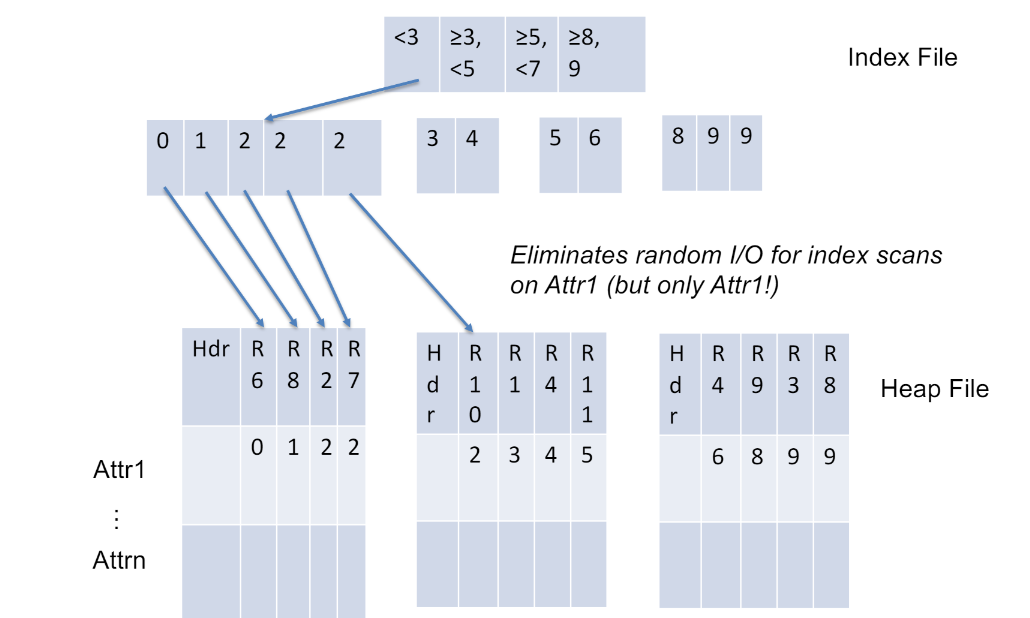 index를 붙이는 것 뿐아니라 물리적으로도 정렬해 두는 것!
index를 붙이는 것 뿐아니라 물리적으로도 정렬해 두는 것!
(cost 때문에 아주 중요한 data가 아닌 경우 이것 안함)
Connecting Operators: Iterator model
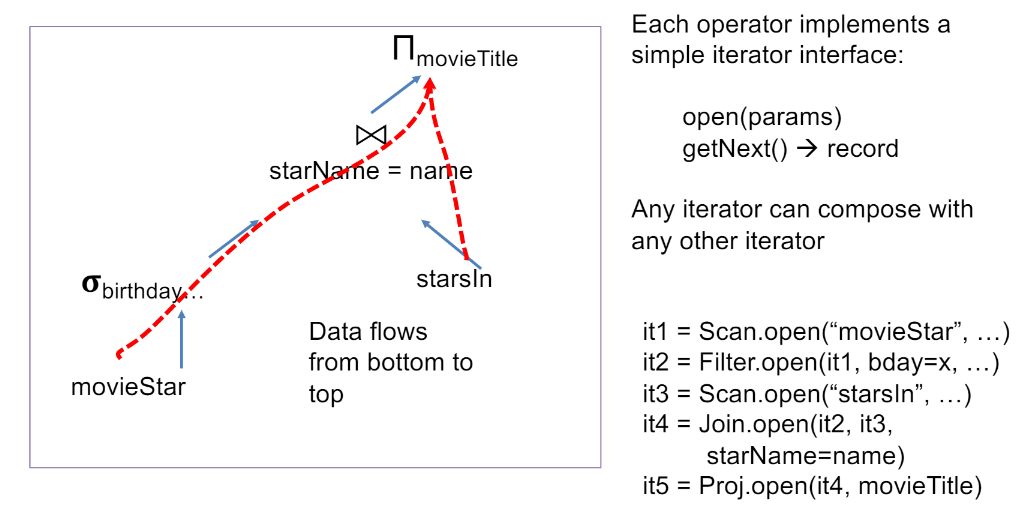 좌측과 같은 plan을 토대로 logical plan세울 수 있다.
좌측과 같은 plan을 토대로 logical plan세울 수 있다.
또한 이후 각각을 물리적으로 구현
출처 : 2023-2 ITE2038 수업