Database Design and Normalization
ITE2038 Database Systems
Contents:
- Relational database design
- Normal forms
Entity Relationship Modeling
Zoo data로 전에 봤던 entity relationship modeling
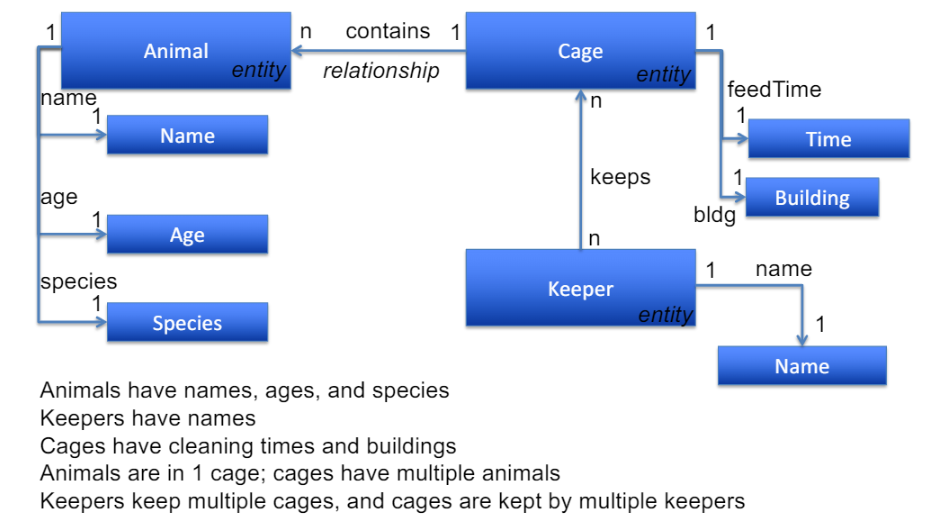
ER Diagrams
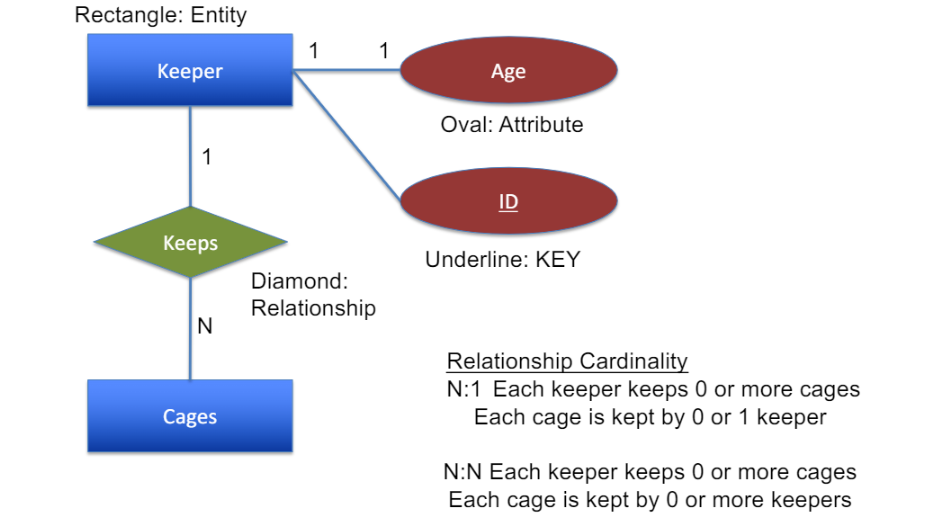
entity, attribute에 치중하느라 relationship 무시하면X
$\because$ 1to n인지 n to n인지에 따라 table 하나 더 만들어야 하는 경우도 있음
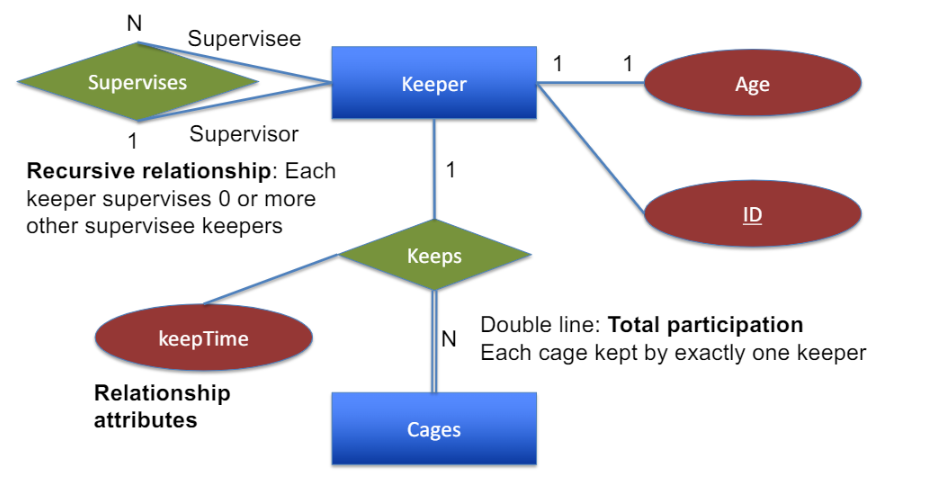 관리자들 간에도, 관리자가 여러 관리자 관리할 수 도 있고 관리 당할수도 O
-> recursive relationship
관리자들 간에도, 관리자가 여러 관리자 관리할 수 도 있고 관리 당할수도 O
-> recursive relationship
double line: 빠지는 것 없이 모두가 이 관계에 참여
cage중에 사육사가 관리 안하는 cage X
ER diagram -> realtion
위의 다이어그램을 relation으로 표현하면,
Keepers: (ID, age, supervisor REFERENCES Keepers.ID ...)
Cages: (keptby NON NULL REFERENCES Keepers.id, keepTime, ...)
keeper당 superviser 1명이기 때문에 이렇게 쓸 수 O. 아니라면 더 쪼개야 함.
keeper는 supervisor와 keeper.ID를 통해 연결.
Cages 측면에서 봐도 마찬가지. cage 당 keeper 1명이어서 가능. Cage당 사육사 ID 여러개라면 relationship table 별도로 있어야 함.
$\therefore$ 정확히 relation 쓰는 것. 1:n, n:n
만약 위의 두 관계 모두 n:n이라면? –> table 더 쪼개야 함
Keeps: (ID, age)
Cages: (CageID, ...)
Keeps: (kid, cid, keepTime)
Supervises: (supervisor_kid, supervisee_kid)
Hobbies Example
사람들과 그들의 취미에 대한 database를 생각해보면,
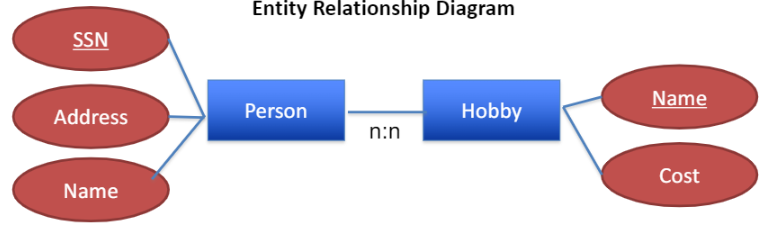 사람들은 이름, 주소를 가지고 취미는 비용을 가지고 있음.
사람들은 이름, 주소를 가지고 취미는 비용을 가지고 있음.
사람은 여러 취미 가질 수 있고, 취미는 여러 사람에 의해 실행될 수 있다.
이를 table로 만들어보면,
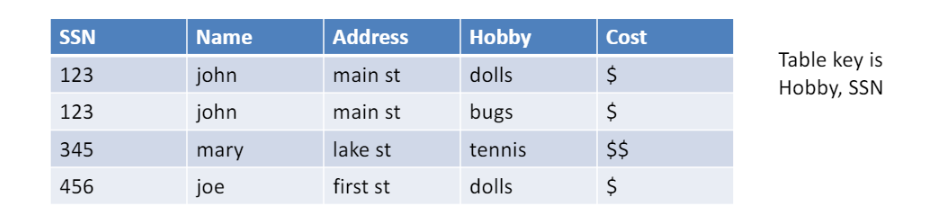 좌측 세 열은 사람관련 data, 우측 두 열은 취미 관련 data
좌측 세 열은 사람관련 data, 우측 두 열은 취미 관련 data
-> 성격 다른 data가 한 table에.
table 안에서 record unique하게 구분 위한 primary key가 1개 아님.
[ "Wide" schema ]
단점1) 중복(redundancy)이 있음 (공간 낭비)
한 사람이 취미 10개면, 사람에 대한 정보 10개
단점2) updates, inserts, deletes가 있을때 anomaly 발생
update: 취미 10개인 사람의 주소가 변경된 경우, 10개 data 다 수정해야 db가 결함 없는 상황이라는것.
(9개만 고치면, 옛주소와 현주소 섞여 있게 됨.)
insert: primary key는 보통 ‘not null’조건.
하지만 여러 attribute로 primary key가 구성되어 있으면, 두 값 다 있어야 데이터 넣을 수 O.
$\therefore$ 취미 없는 사람은 data에 넣을 수 X
delete: mary가 더이상 테니스 안 하는 경우, primary key가 null일 수 없기에 사람 정보포함된 그 행 전체가 지워짐
->이러한 문제 사라지면 데이터 다루기 좋아짐.
= 데이터 일관성 있게 유지 가능
장점) Join 피할 수 있음
Anomaly (=변칙)
Types of anomalies
- Update anomaly
E.g. 주소가 여러곳에서 수정되어야 하는 경우
- 모순 가능성 발생
- Insertion anomaly
- key가 NULL이면 DB에 넣는것 불가
primary key는 보통 ‘not null’조건.
하지만 여러 attribute로 primary key가 구성되어 있으면, 두 값 다 있어야 데이터 넣을 수 O.
- key가 NULL이면 DB에 넣는것 불가
=> 해결책 : “Normalize“ !
다만, 아무렇게나 쪼개면 안됨
(데이터 중간에 사라지지 않고, data 사이의 관계 최대한 유지)
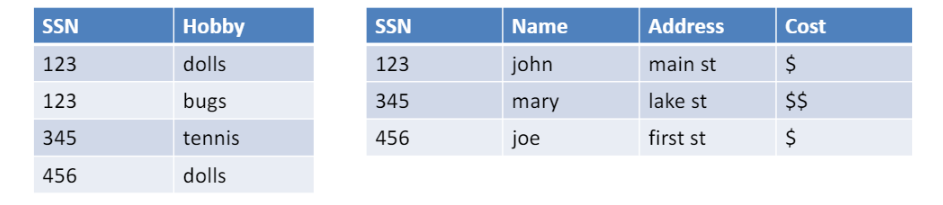 -> 나쁜 분할의 예시
-> 나쁜 분할의 예시
- “Lossy decomposition” (손실 있는 분해)
- 중복은 없지만 의존성(dependency)잃음. 따라서 정보 잃음(hobby의 cost. -> 이 둘은 같은 table에 있어야 함)
Normalization
-
Normalized: 중복 최대한 없는 schema
-
dependencies는 최대한 유지
-
몇가지 방법:
- ER Diagrams
- functional dependencies and normal form
정규화 하는 것:
DB에 data넣어야 하는데 entity와 relationship에 대한 틀을 스키마로 제공.
& 이걸 db에 입력해야 data 넣을 수 있음.
그리고 이 schema를 디자인 하는 방법이 “정규화”임
어떤 object를 attribute로 정의 할 것인지
attribute간의 relation도 최대한 유지.
-> 이걸 만족시키면서 쪼갤 수 있는 규칙: 정규화
=> 좋은 schema 만들기 위해 normalize!
Schema from ER Diagram
ER diagram으로부터 만들어진 schema는 중복에서 자유롭다
왜 recundancy 발생?
: functional dependency 때문
Functional Dependencies

……(여기까지)……> ER로 schema 만드는 방법
Normalization Rules
- 1NF: No repeating groups
= 반복되는 group 없어야 함 - 2NF: No partial dependencies
= key 아닌 attribute가 key 전체에 의해 결정되어야 함 - 3NF: No transitive dependencies
= key 아닌 attribute간의 종속성 있으면 안됨 - BCNF: All determinants are candidate keys
= key 아닌게 key의 일부 결정하면 안됨(이런 종속성 남아있으면 안됨) 4NF: No multi-valued dependencies5NF: No join dependencies
어떤 table이 join으로 생성할 수 있는 상태면 안됨(A와B를join한 결과가C면 table은 C형태면 안됨)
dependency를 계속 따지는 것. $\because$ dependency있으면 중복될 수밖에 X.
$\therefore$이걸 제거해 주는 것. (계속 종속성 분리)
4NF, 5NF는 실용적이라기 보단 이론에 가까움.
너무 많이 쪼개면 data간의 관계(연관성) 사라짐
대부분의 database는 database anomaly 피하기 위해 3NF 혹은 BCNF이 되어야 함.
3NF보다 BCNF가 더 많이 쪼갬. but, attribute 사이의 dependency 사라질 수 O (어떤게 더 좋다는 건 없음.)
$\therefore$ data구조 설계하는 사람의 선택
 차수높아질수록 중복 줄어들고, table 많아지고, 규칙 복잡해짐
차수높아질수록 중복 줄어들고, table 많아지고, 규칙 복잡해짐
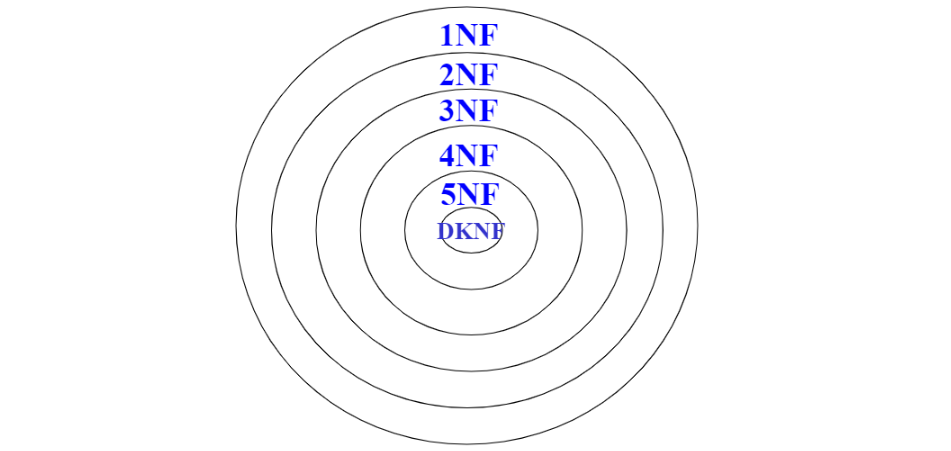 높은 단계와 subset 관계.
높은 단계와 subset 관계.
높은 정규화 규칙 조건에 낮은 차수 충족 먼저 해야한다는 것 있음
First Normal Form (1NF)
1NF 정의
1NF 만족한다
= table의 값에 list가 아닌 scalar값만 포함하고, 반복되는 group이 없는 상황
- only scalar values
- no repeating groups
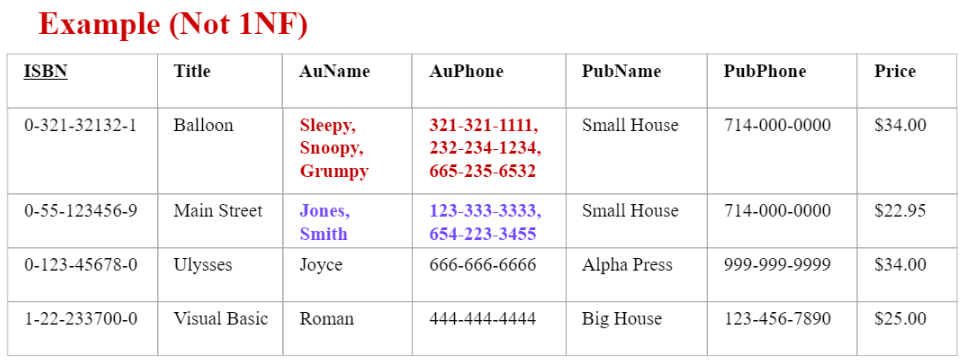
scalar가 아닌 list 포함하는 예시반복되는 group 예시
Decomposition (1NF 조건 만족하도록)
- reapeating group 새로운 table에
- 새로 생성한 table의 primary key 지정
- 기존 table에서 primary key를 새 table에 복사
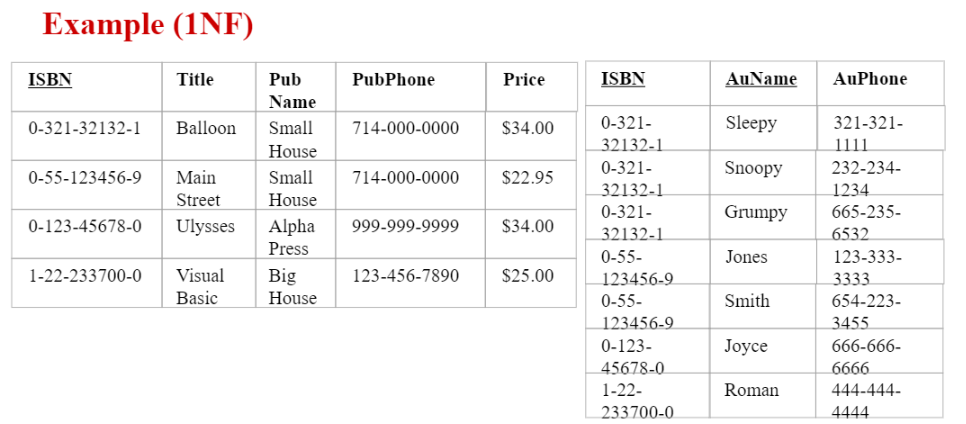 (우측의 기본 table에서 repeating group 쫓아낸 table에서) ISBN만으로 record unique하게 구분 불가 $\because$저자 여러명.
(우측의 기본 table에서 repeating group 쫓아낸 table에서) ISBN만으로 record unique하게 구분 불가 $\because$저자 여러명.
$\therefore$ (ISBN & 저자명) 두개 조합으로 primary key
Second Normal Form (2NF)
2차부터 functional dependency, primary key 고려해야 함.
Functional Dependencies
table의 한 set의 attribute가 다른 set의 attribute를 결정한다면,
두번째 set의 attribute가 첫번째 set에 “functionaly dependent”하다고 함
Primary key
- table 전체에서 각 record를 유일하게 구분할 수 있는 attribute 1개 혹은 attribute집합을 ‘candidate key‘라고 함. (record 전체 생각하면 record 전체는 candidate key 될 수 있음. : 여러개 set 가능하다)
- 이 candidate key 중 가장 작은 것이 primary key
두개 이상의 attribute 가진 key는 composite key라고 함.
primary key가 candidate key 중 가장 작은 set이므로 primary key 의 일부가 candidate key이면 안됨.
Primary key
unique 하게 레코드 구분할 수 있게 하는 attribute중 최소
Foreign key
table 쪼개면 관계 사라짐.
$\therefore$ 다시 2개 합쳐야(join 해야) attribute 사이의 관계 복원 가능.
-> 이때 사용하는 것이 ‘foreign key’
Foreign key
table 분히라는 경우, 두개 연결하는데 사용되는 key
2NF 정의
- 1차정규형(1NF) 조건 충족
- 모든 non-key attribute는(key아닌건) primary key전체에 의존해야 함
(= primary key 일부에의해 결정되면 안됨)
❗주의
non-key attribute에 집중하고 있음

위 예시에서 2차조건의 확인은,
“price, AuAddress가 primary key 전체가 아닌 일부에 의해 결정될 수 있는가?” 고민
파란 부분처럼 AuAddress는 AuID만 있어도 결정 가능.
바라지 않은 종속관계가 있는 것
$\therefore$ 2NF만족 X (쪼개야 만족)
Decomposition (2NF 조건 만족하도록)
- primary key 일부에 의존 하는것들을 새 table로
- 동일한 부분에 의존하는 다른 데이터 있으먼 그것도 같이 옮기기
- 의존하던 일부분을 복사해와서 primary key로 설정

Third Normal Form (3NF)
3NF 정의
3NF 만족한다
= key 아닌것들간의 종속관계 없어야 함.
2NF는 key아닌것에 집중. key 일부에 종속되는지 확인했었음.
3NF는 key 아닌것들 한정으로 관계 확인.
- 2차정규형(2NF) 조건 충족
- key 아닌것들 간의 종속관계 없어야함
(= key 아닌것이 key 아닌걸 결정하게되면 안됨)
파란 부분처럼 primary key가 아닌 것 간의 종속성 있다면 다른 table로.

Decomposition (3NF 조건 만족하도록)
- key 아닌것들 간의 종속관계 O -> 새 table로
- 각 table에 대해 적절히 primary key 설정
- 쪼갰지만 원래 table로 연결방법 있어야 하니 foreign key도 적절히 설정

Boyce-Codd Normal Form (BCNF)
BCNF 정의
BCNF 만족한다
= table에서 key는 하나여야 한다. key 아닌것이 key중 일부 결정할 수 있으면 안됨.
BCNF만족여부 찾고싶으면,
- candidate key 2개이상 찾고,
- 그 candidate key들이 2개이상으로 구성, 그리고 그 중 겹치는 게 있다면,
- BCNF 아닌것.
파란 부분처럼 primary key가 아닌 것이 primary key중 일부 결정한다면 다른 table로.

Decomposition (3NF 조건 만족하도록)
- candidate key 2개 있으니, 하나를 primary key로 쓰고 하나는 다른 table로
- attribute 배분, primary key 정하고, 연결고리로 foreign key 지정.

❗deconposition 시 Loss of Information주의
정규화 진행하면서 decomposition 수행 시,
정보 잃어버리면 안되고, 둘 사이의 관계(dependency)잃어버리면 안됨.
-> schema decomposition할 때 개인의 판단 적절히 사용하는 것 중요.
BCNF 충족시키는 과정에서 loss of info 주의해야하는 예시


차수별로 종속성의 종류가 다른 것.
결국 종속성을 찾고, 종속성 가진 것을 별도의 table로 분리.
잘게 쪼개면 join의 문제이긴 함. (차수 높아질 수록)
but, 그럼에도 data 중복성 제거해서 anomaly 제거하는게
(join 짧아지는것보다) db가 중복 제거 통해 이상한 상태에 있지 않게 방지하는 것이 더 좋다고 생각.
결국 정규화는 좋은 schema를 얻을 수 있는 규칙
+관계형 DB는 data를 set으로 처리.
-> 중복 X (각 record는 table에서 unique해야 함)
Recap
- Properly normalized schema는 중복을 피하고 dependency를 유지한다
- 방법 1) 정규화
functional dependency와 BCNF와 같은 normal form은 정형화된, 실수 적게하는 방법 -
방법 2) ER modeling
ER 그리는 방법은 BCNF 알고리즘을 사용하지 않고 BCNF를 끌어내는 방법이다. - (방법은 크게 중요하지 않음. 결국 좋은 스키마를 만들기 위한 여러 방법들일 뿐.)
다음시간:
-
database internal
출처 : 2023-2 ITE2038 수업